“Feminism is for everybody”
bell hooks
Introduction
The Quotebank dataset was created on the premises that while quotations are interesting materials by themselves, with an attributed speaker more meaning can be infered (see research paper). In this data story we build upon these premices to ask a few questions about women’s rights and gender equality rhetoric in news articles.
Our questions will make use of the data that contextualize the quotations in Quotebank, namely the date, attributed speaker and the quotations themselves. We will explore who relies on arguments of women’s rights and gender equality, using additional datasets to complete the social profile of the attributed speaker. We are also interested in discovering in which social and political context this rhetoric is used. To this end, we will use additional datasets and natural language processing to higlight some possible links between political events and the evolution of feminist topics in news articles.
Our dataset
Our starting dataset is a selection of quotations about feminism and gender equality. The selection was based on a list of keywords created both manually and automatically. This approach aims at reducing the bias of an exclusively manual keywords list or automatic keywords selection. For the automatic keywords, we scraped the usnews website because they have some topic pages that list all articles on the specified topic. The articles belonging to 5 subjects were selected to form a corpus.
feminism gender gender_bias sexism women's rights
From this corpus a list of the frequent bigrams were retrieved. We decided to not count one-grams because they are too general for our purpose, for example women gives a lot of results but they are not always of interest. Finally we end up with a list of 64 keywords used to retrieve quotation from the Quotebank dataset. The final dataset has 87’161 entries related to women’s rights and gender equality rhetoric.
| Keywords | Number of articles | Quotations | Number of words | Years |
|---|---|---|---|---|
| 64 | 173,557 | 87,161 | 2,324,961 | 5 |
In order to decipher what we have in our dataset we created categories within our feminist dataset. The selection keywords were used to split our dataset into 10 categories.
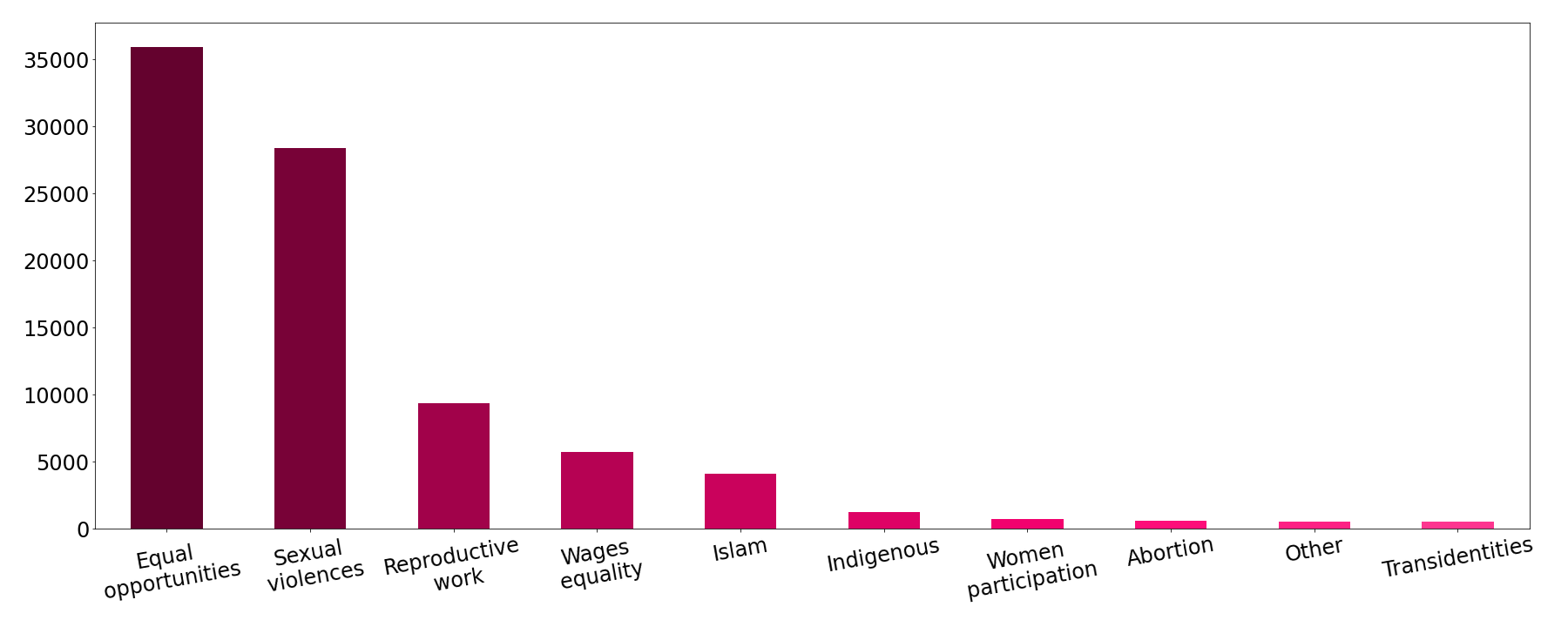
Fig.1 - Quotations distribution over 10 categories. There are 87,161 quotes, from 2015 to 2020.
This supervised method is used to facilitate further investigation on the data by topic. However a few comments are necessary to understand the limitations of such a method. First, some categories have more keywords than other, Indigenous and Sexual violence have respectively 1 and 5 keywords. This can be explained by the fact that the corpus of articles comes from observational data, therefore even at this level our keywords aren’t representative. In addition, the data scientist is more likely to add keywords related to their own situated knowlege1. Note also that the quotations themselves come from observational studies as they have been collected from news articles a posteriori. Therefore it is not guaranted that there isn’t any confounder.
For example it is well known that news article rarely acknowledge feminicide as such (see Data Against Feminicide Project for more information). In this case the low percentage of quotations related to the topic is mainly due to the fact that it is a tabou topic and that no effort can be made to control the data a priori. In our dataset, only 2 quotations mention feminicide.
“We will spare no effort to address discrimination and violence against women, especially feminicide and sexual harassment” Damares Alves
“setbacks to women’s rights, alarming levels of feminicide, attacks on women’s rights defenders, and the persistence of laws and policies that perpetuate submission and exclusion” Antonio Guterres
We would like to attract reader’s attention to another problematic specific to our topic. Since the 1990’s intersectionality – interconnection of race, class, ability and other system of oppressions with gender oppression – has become a focus of feminism. In treating data related to such topics looking at one oppression at a time is likely to miss some important conclusions (see Data Feminism for more information). To start, in the next post we look into an unsupervised method as a way to include more dimensions to our categorization.
Methods
Webscraping for keywords retrieval
To scrape news websites and extract keywords related to women’s right topic we use python libraries that parse html trees (BeautifulSoup) and natural language processing (NLTK) to get the most frequent bigrams. The format of the website has to be manually inspected to define the relevant tag contents. In our case, two tags identifying the column of interest in the primary website page as well as a tag to identify the article itself in the secondary pages are manually determined. The article’s content is cleaned with regular expressions to keep only the relevant part of the text (e.g. copyright ignored).
Keywords
women's right equal opportunities equal rights equal status equal pay gender gap gender discrimination gender equality sexual harrasment
women empowerment women victim women immigration women emancipation women's participation western women non-western woman Muslim women Muslim woman equal wages gender equality gender equity men and women women and men women oppression abortion niqab ban struggle of girlsstruggle of women war against women oppression of girls oppression of women women oppression women's opression liberate women religious oppression abuse of women male oppression female oppression exploitation of women Indigenous women patriarchal culture gender equality child care men pay percentage men pay percentage sexual harassment women girls girls women rates women women according female mayors share women women movement see women gender stereotypes gender gap women representation sex discrimination women rights woman time based gender female candidates gender-based violence entirely female
-
In this study the data scientist choosing the keywords is a white, cisgender, middle-class, able women. ↩